
描述
可以从2×2表中输入的数据计算测试特征,例如敏感性,特异性,阳性和阴性的似然比,疾病患病率以及阳性和阴性的预测值。
必填项
输入患病组中测试阳性和阴性的病例数(左列);以及未患病组中呈阳性和阴性的病例数(右栏)。
注意:您可以通过单击![]() 按钮来更改列和行的顺序。
按钮来更改列和行的顺序。
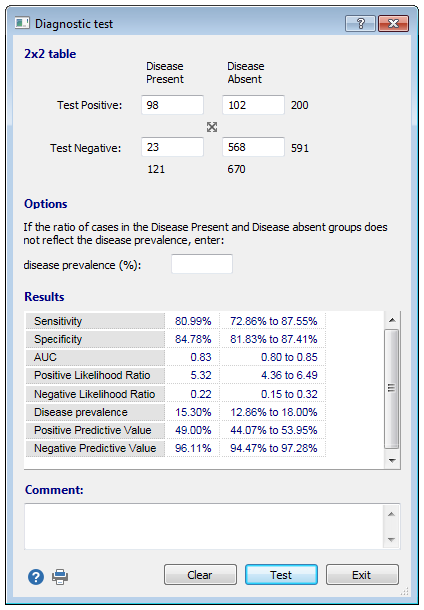
疾病流行
如果阳性(存在疾病)和阴性(不存在疾病)组中的样本大小不能反映疾病的实际患病率,则可以在相应的输入框中输入疾病患病率。这将对正预测值和负预测值以及准确性产生影响。
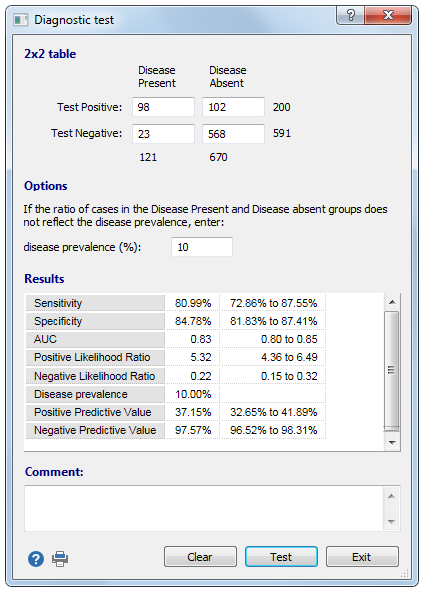
结果
报告以下统计信息,其置信区间为95%:
- 敏感性:疾病存在时检测结果为阳性的概率(真实阳性率)。
- 特异性:当疾病不存在时检测结果为阴性的可能性(真阴性率)。
- AUC:ROC曲线下的面积。
- 阳性似然比:在存在疾病的情况下呈阳性测试结果的概率与在不存在疾病的情况下呈阳性测试结果的概率之比,即
=真阳性率/假阳性率=敏感性/(1 −特异性)
- 负似然比:在存在疾病的情况下呈阴性结果的概率与在不存在疾病的情况下呈阴性结果的概率之比,即
=假阴性率/真阴性率=(1 −敏感性)/特异性
- 阳性预测值:测试呈阳性时疾病存在的概率。
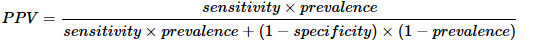
- 阴性预测值:测试阴性时疾病不存在的概率。
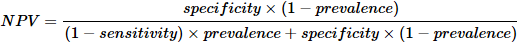
- 准确性:正确分类患者的总体可能性。
=灵敏度×患病率+特异性×(1 −患病率)
敏感性,特异性,疾病患病率,阳性和阴性预测值以及准确性均以百分比表示。
敏感性,特异性和准确性的置信区间是“精确”的Clopper-Pearson置信区间。
似然比的置信区间使用Altman等人在第109页上给出的“对数法”进行计算。2000。
预测值的置信区间是Mercaldo等人给出的标准logit置信区间。2007年。
在注释输入字段中,您可以输入将包含在打印报告中的注释或结论。