
| 命令: | 统计 ROC曲线 ROC曲线 ROC曲线分析 ROC曲线分析 |
描述
允许创建ROC曲线和完整的敏感性/特异性报告。ROC曲线是诊断测试评估的基本工具。
在ROC曲线中,针对参数的不同截止点,根据假阳性率(100-特异性)绘制了真实阳性率(灵敏度)。ROC曲线上的每个点代表对应于特定决策阈值的灵敏度/特异性对。ROC曲线下的面积(AUC)用来衡量参数可以区分两个诊断组(患病/正常)的程度。
理论总结
使用接收器工作特征(ROC)曲线分析评估测试的诊断性能或区分正常病例的测试准确性(Metz,1978; Zweig&Campbell,1993)。ROC曲线也可用于比较两个或多个实验室或诊断测试的诊断性能(Griner等,1981)。
当您考虑在两个人群中一个特定测试的结果时,一个人群患有疾病,另一个人群没有疾病,您很少会观察到两组之间的完美分离。实际上,测试结果的分布将重叠,如下图所示。

对于您选择用来区分两个人群的每个可能的临界点或标准值,有些疾病被正确分类为阳性(TP =真阳性分数),但是某些疾病被分类为阴性( FN =假负分数)。另一方面,某些没有疾病的病例将被正确地分类为阴性(TN =真阴性分数),而有些没有疾病的病例将被分类为阳性(FP =假阳性分数)。
测试的示意图结果
下表中列出了不同的部分(TP,FP,TN,FN)。

可以定义以下统计信息:
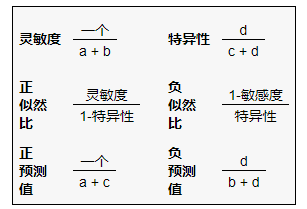
- 敏感性:当疾病存在时测试结果为阳性的概率(真实阳性率,以百分比表示)。
= a /(a + b) - 特异性:不存在疾病时测试结果为阴性的概率(真实阴性率,以百分比表示)。
= d /(c + d) - 阳性似然比:在存在疾病的情况下呈阳性测试结果的概率与在不存在疾病的情况下呈阳性测试结果的概率之比,即
=真阳性率/假阳性率=敏感性/(1-特异性) - 阴性似然比:给出的阴性测试结果的概率之比存在该疾病的和给出的阴性测试结果的概率不存在该疾病,即
=假阴性率/真阴性率=(1-灵敏度)/特异性 - 阳性预测值:测试呈阳性时疾病存在的概率(以百分比表示)。
= a /(a + c) - 阴性预测值:测试阴性时疾病不存在的概率(以百分比表示)。
= d /(b + d)
敏感性和特异性与标准值
当您选择较高的标准值时,假阳性率会随着特异性的提高而降低,但另一方面,真阳性率和灵敏度将降低:

当选择较低的阈值,则真阳性率和灵敏度会增大。另一方面,假阳性率也将增加,因此真正的阴性率和特异性将降低。
ROC曲线
在接收器工作特性(ROC)曲线中,针对不同的截止点,真实的阳性率(灵敏度)是虚假阳性率(100-特异性)的函数。ROC曲线上的每个点代表对应于特定决策阈值的灵敏度/特异性对。具有完美判别力的测试(两个分布中没有重叠)的ROC曲线穿过左上角(灵敏度为100%,特异性为100%)。因此,ROC曲线越靠近左上角,测试的整体准确性就越高(Zweig&Campbell,1993)。

如何输入数据进行ROC曲线分析
为了在MedCalc中执行ROC曲线分析,您应该有一个感兴趣的测量(=您想要研究的参数)和一个独立的诊断,该诊断将您的研究对象分为两个不同的组:患病组和非患病组。后者的诊断应独立于目标测量。
在电子表格中,为诊断变量创建一个DIAGNOSIS列和一个列,例如TEST1。为每个研究对象输入以下诊断代码:1用于患病病例,0用于未患病或正常病例。在“ TEST1”列中,输入感兴趣的度量(可以是度量,等级等-如果数据是分类的,请用数值对它们进行编码)。

必填项
完成“ ROC曲线分析”对话框,如下所示:

数据
- 变量:选择感兴趣的变量。
- 分类变量:选择或输入表示诊断的二分变量(0 =阴性,1 =阳性)。
如果数据的编码方式不同,则可以使用“定义状态”工具重新编码数据。
- 过滤器:(可选)过滤器,以便仅包括案例的选定子组(例如AGE> 21,SEX =“ Male”)。
方法论:
- DeLong等。:使用DeLong等人的方法。(1988)计算曲线下面积的标准误差(推荐)。
- Hanley&McNeil:使用Hanley&McNeil(1982)的方法计算曲线下面积的标准误差。
- AUC的二项式精确置信区间:计算曲线下面积的精确二项式置信区间(推荐)。如果未选择此选项,则置信区间的计算方式为标准误差的AUC ±1.96。
疾病流行
尽管敏感性和特异性以及ROC曲线以及阳性和阴性可能性比与疾病患病率无关,但是阳性和阴性预测值高度依赖于疾病患病率或疾病的先发概率。因此,当疾病患病率未知时,程序无法计算阳性和阴性预测值。
在临床上,疾病患病率与进行测试之前出现疾病的可能性(疾病的先验概率)相同。
- 未知:当疾病患病率未知或与当前统计分析无关时,请选择此选项。
- 阳性和阴性组中病例的比例反映出该疾病的患病率:如果阳性和阴性组中的样本量反映出该疾病在人群中的实际患病率,则可以通过选择此选项来表明。
- 其他值(%):或者,您可以输入疾病流行率的值,以百分比表示。
选件
- 列出具有测试特征的标准值:创建与ROC曲线的坐标相对应的标准值的列表的选项,并具有相关的灵敏度,特异性,似然比和预测值(如果已知疾病患病率)。
- 包括所有观察到的标准值:选择此选项时,程序将列出所有可能阈值的敏感性和特异性。如果未选择此选项,则程序将仅列出ROC曲线的更重要的点:对于相等的敏感性/特异性,它将给出具有最高特异性/敏感性的阈值(标准值)。
- 95%的置信区间,用于敏感性/特异性,似然比和预测值:选择所需的置信区间。
- 在考虑成本的情况下计算最佳标准值:考虑疾病流行率以及错误和真实的正面和负面决定的成本来计算最佳标准值的选择(Zweig&Campbell,1993)。仅当已知疾病流行率时,此选项才可用(请参见上文)。
- FPc:误判的成本。
- FNc:错误的否定决定的成本。
- TPc:一个真正积极的决定的成本。
- TNc:真正否定决策的成本。
这些数据用于计算参数S,如下所示:

其中P表示目标人群中的患病率(Greiner等,2000)。考虑到普遍性和不同决策的成本,ROC曲线上具有该斜率S的直线接触曲线的点是最佳工作点。
成本可以是财务成本或医疗成本,但所有4个成本因素都需要以相同的比例表述。收益可以表示为负成本。假设一个错误否定(FN)决策的成本是错误肯定(FP)决策的两倍,并且没有对真正肯定和真正否定决策的成本做任何假设。然后为FNc输入2,为FPc输入1,然后为TPc和TNc输入0。
由于斜率S必须为正数:
- FPc不能等于TNc
- FNc不能等于TPc
- 当TNc大于FPc时,TPc必须大于FNc
- 当TNc小于FPc时,TPc必须小于FNc
当(FPc-TNc)/(FNc-TPc)等于1时,即当FPc-TNc等于FNc-TPc时,参数S为“成本中性”。在这种情况下,S和“最佳标准值”仅取决于疾病患病率。
- 高级:单击此按钮可获得一些高级选项:
这些选项需要自举,并且计算量大且耗时。
- 在固定的特异性和敏感性下的敏感性和特异性的估计:编制一个具有敏感性和特异性估计的表,BC固定为95%的置信区间(Efron,1987; Efron&Tibshirani,1993),用于固定的和预先指定的特异性和敏感性80%,90%,95%和97.5%(Zhou et al。,2002)。
- Bootstrap Youden指数置信区间:计算Youden指数及其相关标准值的自举95%置信区间的BC 。
- 引导程序复制:输入引导程序复制的数量。1000次复制是文献中经常遇到的数字。高数字可提高准确性,但同时也会增加处理时间。
- 随机数种子:这是随机数生成器的种子。输入0作为随机种子;当重复该过程时,这可能导致不同的置信区间。任何其他值将给出可重复的“随机”序列,这将导致置信区间的可重复值。
ROC图
- 选择“显示ROC曲线”窗口以在单独的窗口中获取图形。
选项:
- 标记与标准值相对应的点。
- 显示ROC曲线的95%置信区间(Hilgers,1991)。
结果
样本量
首先,程序显示两组观察值的数量。关于样本量,已经提出可以从总共进行大约100次观测的ROC实验中得出有意义的定性结论(Metz,1978年)。

ROC曲线下的面积,具有标准误差和95%置信区间

此值可以解释如下(Zhou,Obuchowski&McClish,2002):
- 所有可能的特异性值的敏感性平均值;
- 所有可能的灵敏度值的特异性平均值;
- 从阳性组中随机选择的个体具有比对阴性组中随机选择的个体具有更大怀疑结果的测试结果的可能性。
当所研究的变量无法区分两组时,即两个分布之间没有差异时,面积将等于0.5(ROC曲线与对角线重合)。当两组值完全分开时,即分布没有重叠,ROC曲线下的面积等于1(ROC曲线将到达图的左上角)。
95%置信区间是ROC曲线下的真实(人口)区域位于95%置信区间的区间。
显着性水平或P值是在ROC曲线下的真实(人口)面积为0.5(无效假设:Area = 0.5)时发现了ROC曲线下的观察样品面积的概率。如果P小(P <0.05),则可以得出结论,ROC曲线下的面积显着不同于0.5,因此有证据表明实验室测试确实具有区分两组的能力。
尤登指数

尤登指数J(尤登,1950年)定义为:
J = max {灵敏度c +特异性c -1}
其中c覆盖所有可能的标准值。
在图形上,J是ROC曲线和对角线之间的最大垂直距离。
仅当疾病患病率为50%,灵敏度和特异性相等且忽略各种决策成本时,与Youden指数J对应的标准值为最佳标准值。
选择了相应的“高级”选项后,MedCalc将为Youden指数及其相应的标准值计算BC的自举95%置信区间(Efron,1987; Efron&Tibshirani,1993)。
标准值
MedCalc不仅报告阈值或标准值,还根据比较值>或<来报告标准值,具体取决于较高的值表示疾病,较低的值表示疾病。
请参阅有关标准值的注释。
最佳标准
仅在已知疾病流行率和费用参数时才显示此面板。

最佳标准值不仅考虑敏感性和特异性,而且考虑到疾病患病率以及各种决策的成本。当这些数据已知时,MedCalc将计算最佳标准以及相关的敏感性和特异性。并且当已经选择了相应的高级选项,的MedCalc将计算BC一个自举95%置信区间(埃夫隆,1987;埃夫隆&Tibshirani,1993)对这些参数。
当出于筛查目的或排除诊断可能性而使用测试时,可以选择灵敏度更高的临界值;当使用测试确认疾病时,可能需要更高的特异性。
汇总表
当已经选择了相应的高级选项时,才会显示此面板。

汇总表显示了在80%,90%,95%和97.5%的固定和预先指定的灵敏度范围内的估计特异性,以及在一系列固定和预先指定的特异性下的灵敏度估计值(Zhou等,2002),与相应的标准值。
置信区间为BC ,自举率为95%(Efron,1987; Efron&Tibshirani,1993)。
ROC曲线的标准值和坐标

结果窗口的此部分列出了不同的过滤器或截止值及其相应的检测灵敏度和特异性,以及正(+ LR)和负似然比(-LR)。当知道疾病的患病率时,程序还将报告阳性预测值(+ PV)和阴性预测值(-PV)。
当您未选择包括所有观察到的标准值在内的选项时,程序仅列出ROC曲线的更重要的点:对于相等的灵敏度(分别为特异性),它将给出具有最高特异性(最高为阈值)的阈值(标准值)。灵敏度)。当您选择包括所有观察到的标准值选项时,程序将列出所有可能阈值的灵敏度和特异性。
- 敏感性(可选95%置信区间):疾病存在时检测结果为阳性的概率(真实阳性率)。
- 特异性(可选95%置信区间):不存在疾病时检测结果为阴性的可能性(真实阴性率)。
- 阳性似然比(可选95%置信区间):在存在疾病的情况下呈阳性测试结果的概率与在不存在疾病的情况下呈阳性测试结果的概率之间的比率。
- 负似然比(具有可选的95%置信区间):在存在疾病的情况下给出阴性测试结果的概率与在没有疾病的情况下给出阴性测试结果的概率之间的比率。
- 阳性预测值(可选95%置信区间):测试阳性时疾病存在的可能性。
- 阴性预测值(可选95%置信区间):检验阴性时疾病不存在的可能性。
- 费用*:在该决策级别使用诊断测试所产生的平均费用。请注意,此处报告的成本不包括“开销成本”,即进行测试的成本,该成本在所有决策级别均保持不变。
*仅在知道疾病流行率和费用参数时才显示此列。
敏感性,特异性,阳性和阴性预测值以及疾病患病率以百分比表示。
敏感性和特异性的置信区间是“精确”的Clopper-Pearson置信区间。
似然比的置信区间使用Altman等人在第109页上给出的“对数法”进行计算。2000。
预测值的置信区间是Mercaldo等人给出的标准logit置信区间。2007年。
ROC曲线
在对话框中选择相应选项后,ROC曲线将显示在第二个窗口中。

在ROC曲线中,针对不同的截止点,根据假阳性率(100-特异性)绘制了真实阳性率(灵敏度)。ROC曲线上的每个点代表对应于特定决策阈值的灵敏度/特异性对。具有完美判别力的测试(两个分布中没有重叠)的ROC曲线穿过左上角(灵敏度为100%,特异性为100%)。因此,ROC曲线越靠近左上角,测试的整体准确性就越高(Zweig&Campbell,1993)。

单击ROC曲线的特定点时,将显示具有敏感性和特异性的相应截止点。
结果介绍
在不同的临床环境中,疾病的患病率可能不同。例如,当患者咨询专科医生时,其阳性测试的预测试概率将高于其咨询全科医生时的概率。由于阳性和阴性的预测值对疾病的患病率敏感,因此将来自疾病患病率不同的不同研究的这些值进行比较,或将其应用于不同的环境会产生误导。
结果窗口中的数据可以汇总在一个表中。两组中的样本量应明确说明。该表可以包含用于不同标准值的列,相应的灵敏度(CI值为95%),特异性(CI值为95%)以及可能的阳性和阴性预测值。该表格不仅应包含单个截止值的测试特征,而且最好在该行中对应一行,灵敏度分别为90%,95%和97.5%,特异性为90%,95%和97.5 %,以及与Youden索引或最高准确度相对应的值。
有了这些数据,任何读者都可以通过基于贝叶斯(Bayes)的以下公式,在知道该环境中疾病的先验概率(疾病的预检概率或患病率)时,计算适用于他自己的临床环境的阴性和阳性预测值。定理:

和

负似然比和正似然比必须小心处理,因为它们很容易被误解。